
Introducing NotebookLM
What happens when you can explore documents using the power of open-ended conversation?

About five months ago, I shared the news that I was collaborating with Google on a new AI-based tool for thought, then code-named Project Tailwind. If you happened to have missed that post, or are a new subscriber to Adjacent Possible, the quick backstory is that I have had a career-long obsession with using software to augment the research and ideation phase of my work as a writer, some of which I have explored in the “creative workflows” series in this newsletter. About a year and a half ago, the folks at Google Labs reached out to see if I was interested in helping to build a new tool for thought designed around a language model, and that collaboration led to the announcement of Project Tailwind at Google’s I/O conference in May.
A number of exciting developments have happened since then, so I figured it was time for an update. There are two main headlines. First we have dropped the code-name of Project Tailwind, and are now calling it NotebookLM. In the world before computers came along, the primary tool we had for organizing and remixing our ideas and the ideas we encountered in other people’s work was a notebook. This project is what you get when you try to reimagine note-taking software from the ground up knowing that you have a language model at the core. Hence NotebookLM.
The second big headline is that we have started letting people off the waitlist for the early access program, so if you sign up here with a Gmail address, you should be able to get access to the software sometime in the coming weeks. (It is US-only and 18+ for the time being, alas.) As I described in my original post, the core idea behind the current version of the product is what we call “source-grounded AI”: you define a set of documents that are important to your work—called “sources” in the NotebookLM parlance—and from that point on, you can have an open-ended conversation with the language model where its answers will be “grounded” in the information you’ve selected. It is as if you are giving the AI instant expertise in whatever domain you happen to be working in.
One thing that’s important to stress—and I’m sure we will discuss this more in future posts—is this: while it feels like you are interacting with an AI that has been trained on your own personal data, in reality that’s not what’s happening. Without getting too technical about it, when you interact with NotebookLM and ask questions based on your defined sources, we are putting your information into the short-term memory of the model. (Technically called the model’s “context window.”) So if you ask a question about, say, your company’s marketing budget for 2024 based on documents you’ve uploaded, NotebookLM will give you a grounded answer, but the second you move on from that conversation, the quotes are wiped from the models’ memory. So you get all the power of summarization and explanation that the language models give us, but at the same time you can feel secure that whatever personal information you share with NotebookLM will stay private if you choose.
We’ve made a number of improvements to NotebookLM since the version we showed at I/O. We now support PDFs and copied text as sources, along with Google Docs. You can now have 10 sources per notebook, with up to 50,000 words in each source. Because you can opt to focus the model on all your sources, that means that you can effectively have a conversation with a model grounded in half a million words of text. We’ve also started to roll out sharing features, so you can share a collection of sources with other people in your network: sharing work documents with colleagues, say, or panel transcripts with conference attendees, or a syllabus of reading materials with students.
But the feature that I am most excited about intellectually is this: as you interact with the AI in NotebookLM, we dynamically suggest three followup questions for you to ask, based both on the conversation so far and the specific information in your sources. This was a feature that came out of the extensive user testing we’ve started to do with NotebookLM. It hadn’t really occurred to me before how helpful this might be, because as a writer I have a long history of exploring complex ideas by asking questions, usually in the form of interviewing people. But it’s not an approach that always comes naturally to people—in large part because asking open-ended questions of multiple documents was simply not possible until pretty much this year. You could ask questions if you were lucky enough to be able to converse with the author of the documents, or a teacher or tutor who happened to be an expert reader of those documents. But exploring text through the Socratic method of dialogue on your own just wasn’t an option. Source-grounded AI makes this kind of conversational approach possible, and it turns out to be a truly powerful way to explore ideas.
Let me give you an example of how this works in practice. I’ve loaded up the opening five chapters of my book Where Good Ideas Come From as a set of sources in NotebookLM. (As the author of the book, I can do this with confidence because I know NotebookLM is not going to train the model on my data, for the reasons I described above—the information contained in those sources is purely for my own personal use.) With each chapter, NotebookLM generates what we call a “source guide,” offering a short summary of the document, a list of key topics that you can explore, and three suggested questions. So in this case I would start by clicking on the suggested question: How does the liquid network model help explain the rise of human innovation? This is what I get in response:
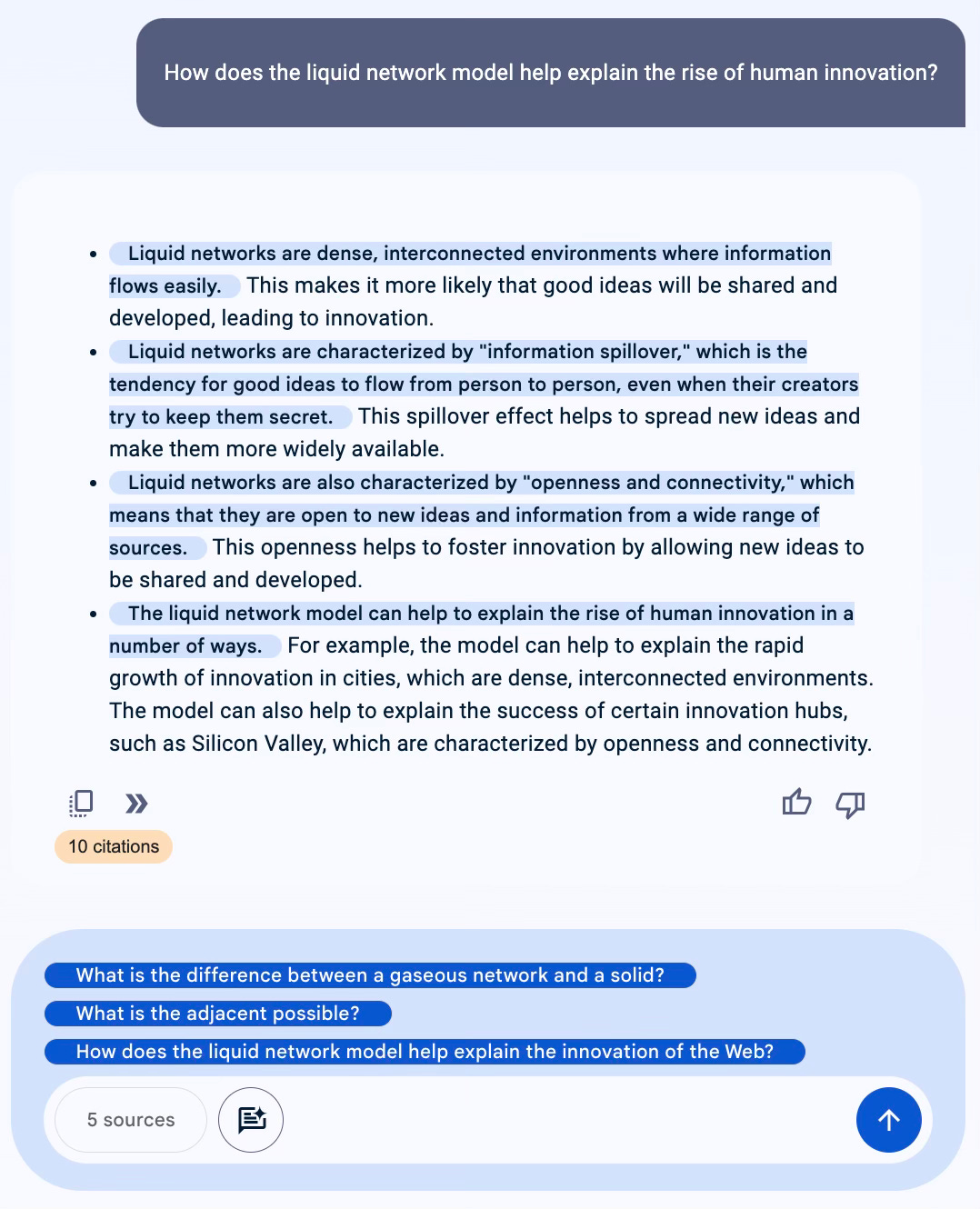
NotebookLM gives me a well-structured overview of the topic, plus a list of citations at the bottom so that I can see the original quotes from my book that it used to answer the question. And then at the bottom: three more questions that lead me to “adjacent” ideas. (Including, naturally, a question about the adjacent possible.) I’ll spare you all the details from the answers, but this is the trail of questions that I followed this morning, just picking from one of the three suggested questions at each step:
What is the difference between a gaseous network and a solid?
What is the role of the network in creativity and innovation?
What is the role of competition in innovation?
How does a city encourage innovation?
What are the benefits of having an open database of hunches?
And in a nicely symmetrical twist, this last one led to a suggested question about DEVONThink, the software I used for many years to organize all my notes and quotations:
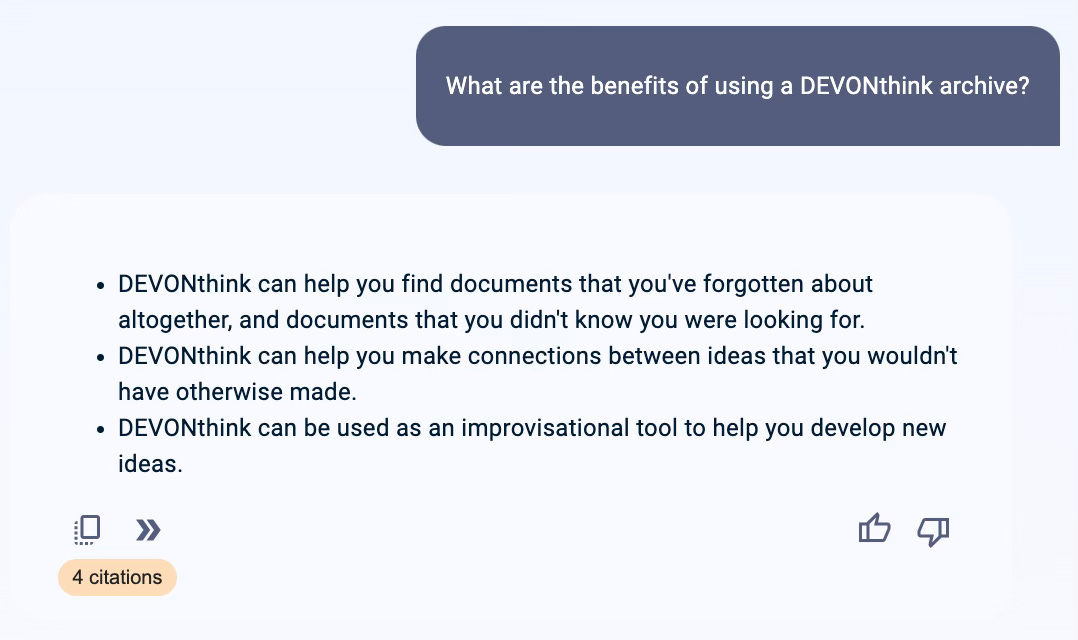
All of those qualities were indeed true of DEVONThink, but of course I never dreamt of actually trying to use it to have an open-ended conversation with my research notes. It simply wasn’t within the adjacent possible of software back then to do such a thing. But now it is.
P.S. One other quick inside look at another of my upcoming projects: we have a subtitle and a jacket cover for The Infernal Machine!

(And just for the record: this post reflects my own personal views and not that of Alphabet or Google Labs.)
Absolutely fascinating. Thank you for the update, and overview. I’m not in the US, but I am definitely over 18, and I would love to try this. (I’m deep into the research phase on my own non-fiction book, and this sounds like it could be incredibly helpful.) If you or someone at Google could add me to the beta list as a favour, I would hugely appreciate it. Happy to give feedback in return. (You could tell them I’m the guy who wrote the ending to Minecraft – the End Poem – if that helps! One of them might be a fan...)
I signed up on the waitlist and can't wait to try it out!